Flink
Ici nous allons utiliser un autre moteur de traitement des flux de données open source : Apache Flink. A l'origine de ce framework, l'idée selon laquelle il est possible de considérer un traitement batch comme un traitement sur un flux de données fini. Dans ce cadre, pourquoi ne pas traiter de manière identique les flux et les batches ? Bon nombre d'applications telles que les analyses en temps réel, le traitement des données historiques (batch), les algorithmes itératifs (machine learning) peuvent ainsi être exécutées comme un pipeline de transformations sur un flux de données.
Flink possède une vaste panoplie de fonctionnalités permettant de répondre aux spécificités de l'analyse "quasi" temps réel en mode distribué sur des flux de données. Parmi lesquelles :
- La capacité de gérer des données aussi bien en mode streaming qu'en mode batch : un dataset étant considéré comme un flux de données fini, les mêmes API pourront être utilisées dans les 2 cas,
- La gestion des cas de retard de la donnée ou encore de donnée non ordonnées, que nous détaillerons plus en détails par la suite,
- La tolérance aux pannes et la restauration de la donnée si un problème survient,
- Une grande scalabilité : flink peut être déployé sur des milliers de noeuds tout en conservant des caractéristiques de performances très élevées,
- Une API en Scala/Java et python en beta,
- Un vaste écosystème donnant accès aux applications de machine learning, de graphe...
Flink se caractérise aussi par des choix d'architecture très originaux comme par exemple la gestion de la mémoire. Il alloue une très large plage de mémoire dans la JVM, et va ensuite gérer lui même les allocations à l'intérieur de celle-ci. Cette approche a pour bénéfice de limiter les impacts du "Garbage Collector" et donc d'avoir des traitements beaucoup plus stables dans le temps.
Principe de fonctionnement
Concrètement, Flink permet à l'utilisateur d'effectuer des transformations sur des données depuis une source. L'utilisateur dispose ensuite de cette donnée processée grâce à un "data Sink".
Event Time, processing, ingestion time et Watermarks:
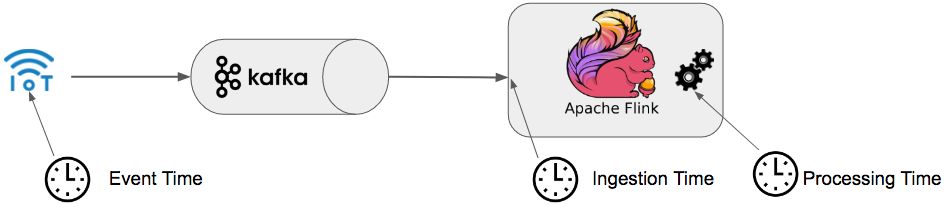
Il est intéressant de se pencher sur la gestion et l'utilisation du temps dans le cadre du traitement de la donnée en environnement streaming. Flink répond à cela en permettant l'utilisation de différents modes:
- Processing Time: pour une opération en cours, il correspond à l'heure de la machine. Chaque opération se basera sur l'heure de la machine pour effectuer ses actions.
- Event time: il correspond au moment de la création de la donnée et est souvent présent sous la forme d'un timestamp. L'event time est inclu dans la donnée elle même.
- Ingestion time: ce temps correspond au moment où la donnée entre dans Flink.
Maintenant que nous avons évoqué ces différentes notions pour prendre en compte une fenêtre de temps, apparaît un problème: comment gérer les messages qui arrivent "en retard" ? En effet, si l'horloge interne d'une machine peut être utilisée lorsqu'il s'agit d'un processing time, on ne peut l'utiliser dans des cas d'ingestion time ou encore d'event time.
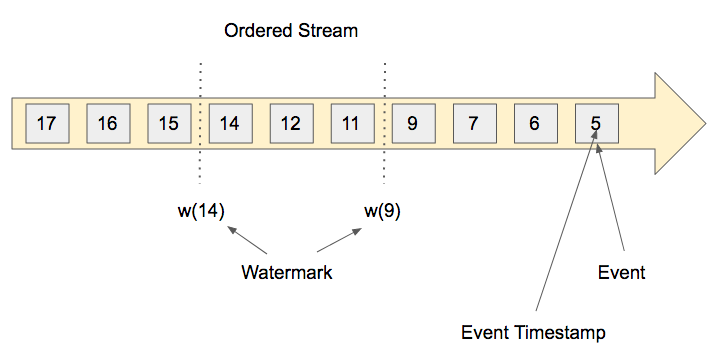
Le principe du Watermark constitue la solution à ce problème dans Flink : il permet d'inclure la notion de temps passé dans un stream.
Un watermark est tout simplement un timestamp, c'est un mécanisme de contrôle intégré au flux lui-même . Lorsqu'une action reçoit un watermark dans Flink, ce dernier comprend automatiquement qu'il ne recevra pas d'évènement plus vieux que ce timestamp.
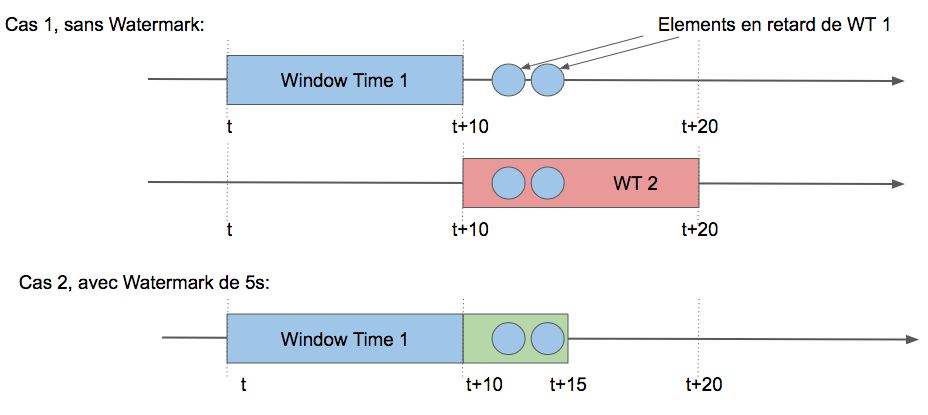
Exemple: Je définis une fenêtre de temps égale à 10 secondes et un watermark current time - 5 seconds. Les traitements seront alors déclenchés avec un délai de 5 secondes.
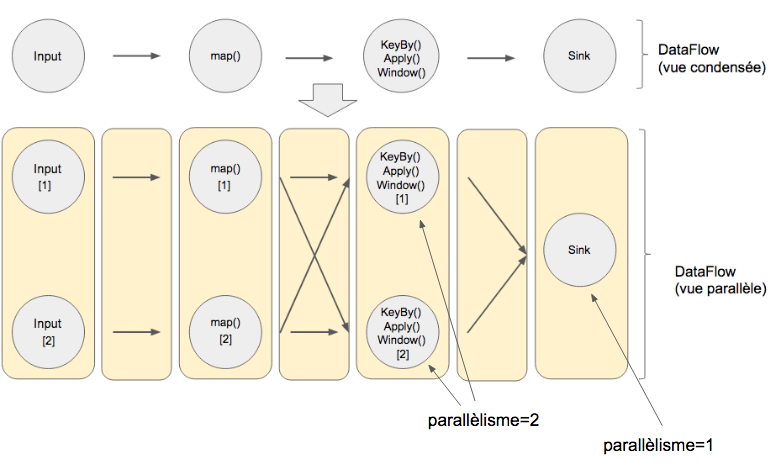
Notion de Parallèlisme:
Flink permet également de gérer la notion de parallèlisme: chaque opération peut être divisée en plusieurs tâches qui tournent en parallèle (ces tâches peuvent être distribuées sur un ou plusieurs noeuds d'un cluster).
Tolérance à la panne:
Que faire en cas d'incident dans le flux stream? Flink se devait de répondre à cette problématique en mettant en place un système permettant de revenir en arrière en cas d'erreur.
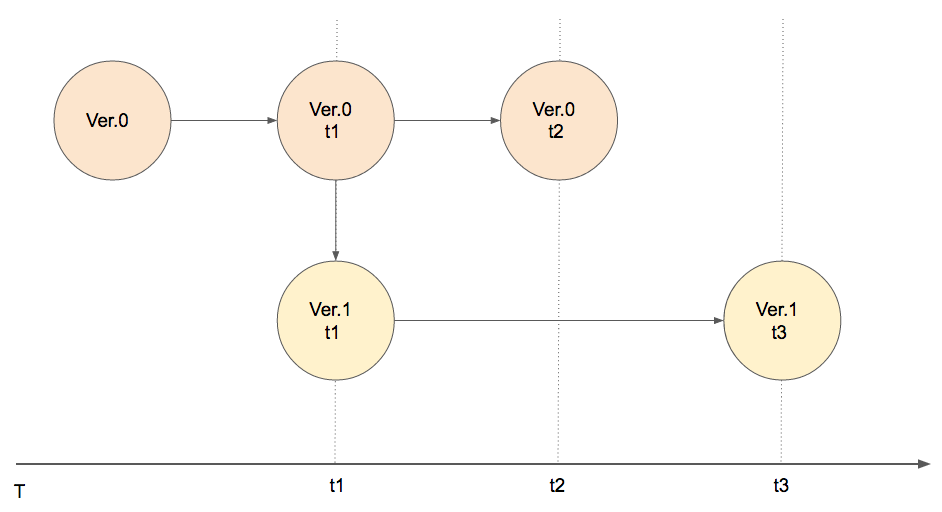
Ce mécanisme se nomme checkpoint. Concrètement, ces derniers fonctionnent comme des images (snapshots) du stream de données. En cas d'erreur, le système pourra revenir au dernier checkpoint avant l'incident.
Remarque : Les savepoints dans Flink se basent sur le mécanisme des checkpoints afin d'écrire les métadonnées du checkpoint dans un fichier système. De ce fait, il est possible de réaliser des mises-à-jour de notre programme Flink sans interruption du système.
Flink au coeur de Boontadata:
L'architecture utilisée repose sur notre plateforme générique boontadata. Elle est constituée des éléments suivants :
- Simulateur IOT permettant de créer des flux de messages
- Système de messagerie distribué Kafka basé sur le principe du "publisher" / "Subscriber"
- Base de donnée Cassandra pour le stockage des données et résultats
- Service de traitement des flux : Flink dans le cas de ce blog post
- Module de comparaison pour évaluer l'impact et la performance du module de traitement
Tous les éléments de la plateforme boontada sont créés dans des containers distincts de manière à apporter un maximum de flexibilité.
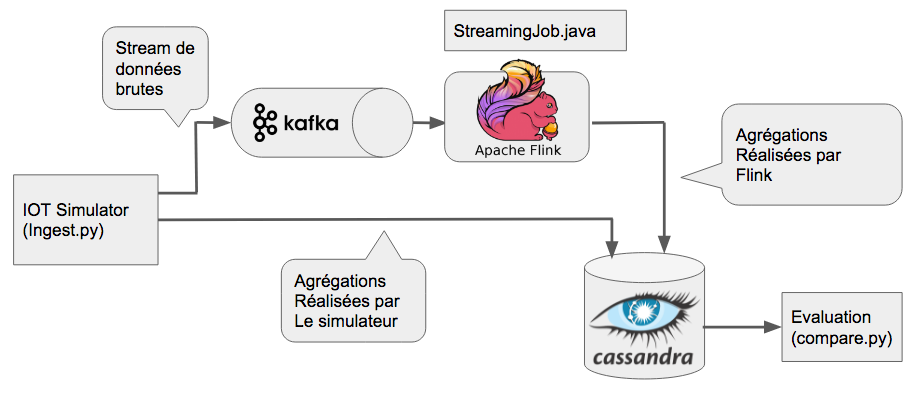
Le schéma ci-dessus représente le workflow de notre plateforme. Les données proviennent d’un IOT et sont envoyées dans un broker Kafka. Les données sources sont également agrégées sur une fenêtre de temps par la simulateur IOT et sauvegardées dans la base Cassandra pour servir de référence. La brique Kafka sert de source de données à Flink qui représente le service de traitement à évaluer. Flink procède au traitement des streams par création de datasets. Ces datasets sont ensuite stockés dans la base de données cassandra (le sink pour Flink). Le module de comparaison récupère les résultats dans Cassandra et permet d'évaluer les latences induites par le traitement Flink.
Afin de connaître la procédure d’installation, n’hésitez pas à aller sur le lien suivant.
Ayant déjà traité le fonctionnement de notre environnement et architecture boontadata dans un blog précédent (voir l'article spark streaming cette série de blog boontadata), nous détaillerons ici le code correspondant au nouveau scénario Flink.
Code:
StreamExecutionEnvironment et récupération des messages Kafka
Pour Flink, le code est écrit en java (StreamingJob.java). Les principaux éléments du code sont les suivants :
- Définition d'un environnement "env" de type "StreamExecutionEnvrinoment", prenant en compte le délai entre la création de checkpoint (5000 msecs) et le parallisme à 2 (2 containers docker en tant que flink workers):
- Comme nous l'avons évoqué précédemment, Flink est à même de gérer le Processing Time, l'Event Time et l'Ingestion Time c'est pourquoi nous avons préparé un scénario pour chacun de ces cas (voir le fichier "runscenario.sh" qui peut prendre 3 arguments: flink1: Processing Time, flink2: Event Time, flink3: Ingestion Time) :
- Les données sont ensuite récupérées depuis notre topic Kafka. On assigne un timestamp et un watermark grâce à la méthode assignTimesstampsAndWatermarks de la class DataStream (librairie: org.apache.flink.streaming.api.datastream.DataStream):
- Comme vous avez pu le remarquer dans le code précédent, on instancie la classe BoundedOutOfOrdernessGenerator au moment de l'appel de la fonction "assignTimestampsAndWatermarks". Cette classe implémente l'interface "AssignerWithPeriodicWatermarks
- Après déduplication et agrégation (somme des mesures) sur une "window_time" de 5 secondes, les données sont envoyées dans cassandra:
- PROCESSING TIME:
- EVENT TIME:
- INGESTION TIME:
On décide de fixer le délai maximal de retard de l'élément à 1 seconde: si un élément arrive dans ce laps de temps, il est attribué à la fenêtre précédente sinon, on le supprime.
De même, la latence maximale liée au processing time est fixée à 6 secondes.
Cette classe retourne deux éléments: un TimeStamp et un watermark
Résultats:
Nous obtenons ainsi 3 résultats selon qu'il s'agisse du traitement par Processing Time, Event Time ou Ingestion Time:
Comparing ingest device and downstream for m1_sum
23 exceptions out of 23
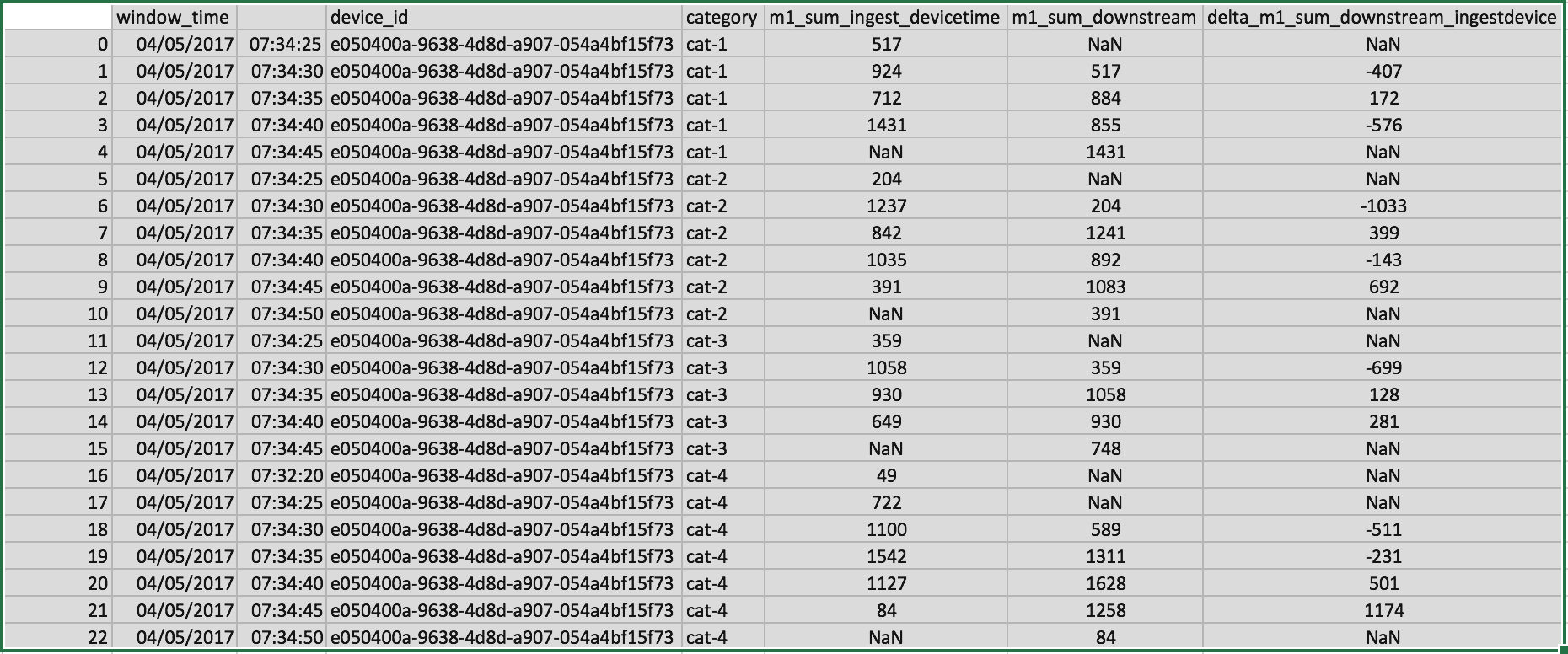
Comparing ingest device and downstream for m1_sum
1 exceptions out of 17

Comparing ingest device and downstream for m1_sum
1 exceptions out of 17

Ces résultats permettent de mettre en évidence les différences de traitements suivant le type de temps qui est mesuré. Les calculs reposant sur l'event time (ou l'ingest time) sont généralement à privilégier quand le moteur de calcul le permet.